AURORA: Active Uncertainty-Driven Re-Orientation for In-Hand Reconstruction
Abstract
Observing objects grasped by a robot hand is challenging due to severe visual occlusions. The manipulator itself obscures large portions of the object, while a fixed camera provides viewpoint-constrained observations. Although these hidden surfaces can be exposed by in-hand manipulation, most existing approaches rely on predefined or open-loop reorientation strategies that do not explicitly target unobserved regions.To address this limitation, we propose AURORA, an active 3D reconstruction framework that leverages in-hand manipulation for object inspection. At the core of AURORA is Ray-GPIS, a novel informative planner that estimates reconstruction uncertainty along candidate viewing rays. By identifying directions that maximize uncertainty-novelty score, Ray-GPIS generates next-best-view targets, which are executed via an axis-conditioned in-hand rotation policy. The resulting visual observations are integrated through a visual fusion pipeline for incremental 3D reconstruction. Extensive real-world experiments on objects with diverse geometries demonstrate that AURORA outperforms baselines, achieving higher surface completeness and faster reconstruction.
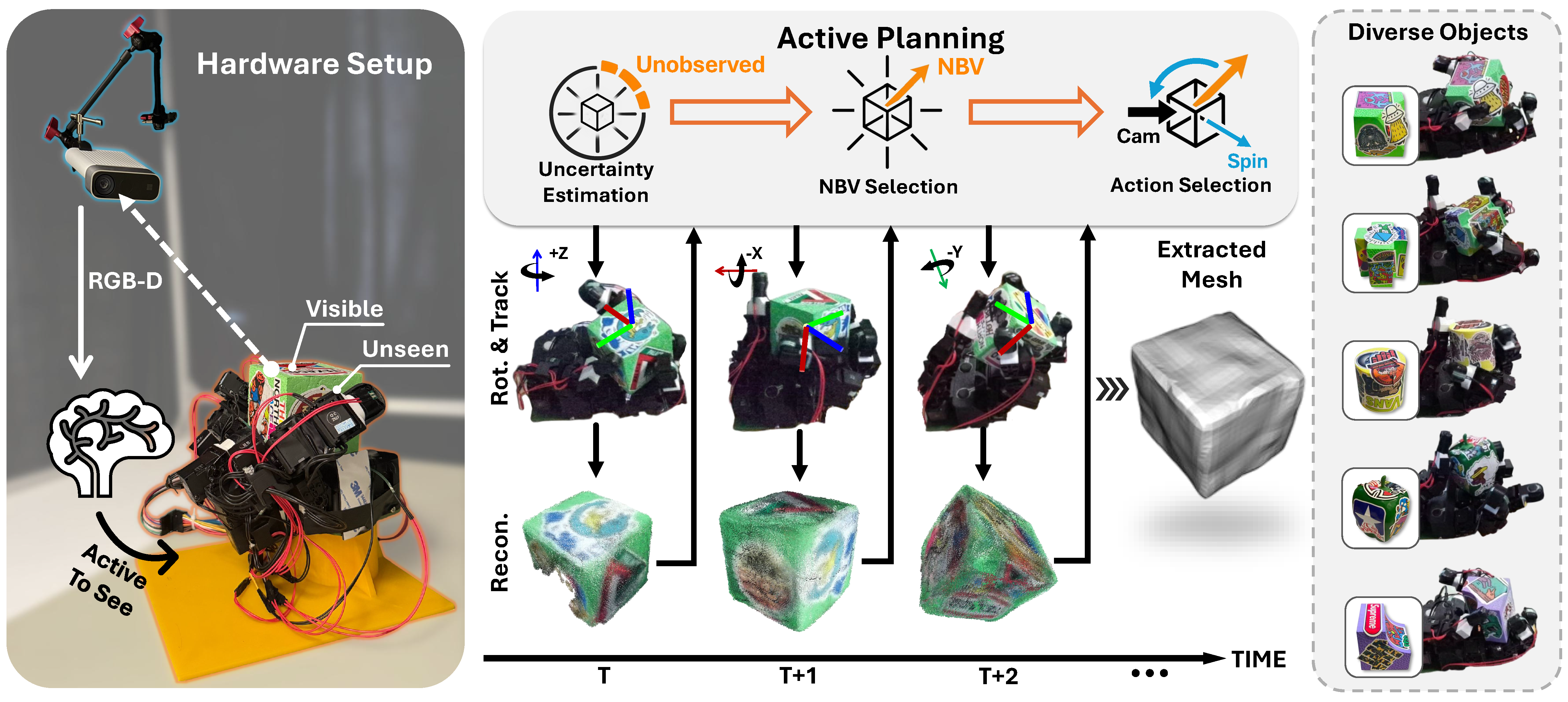
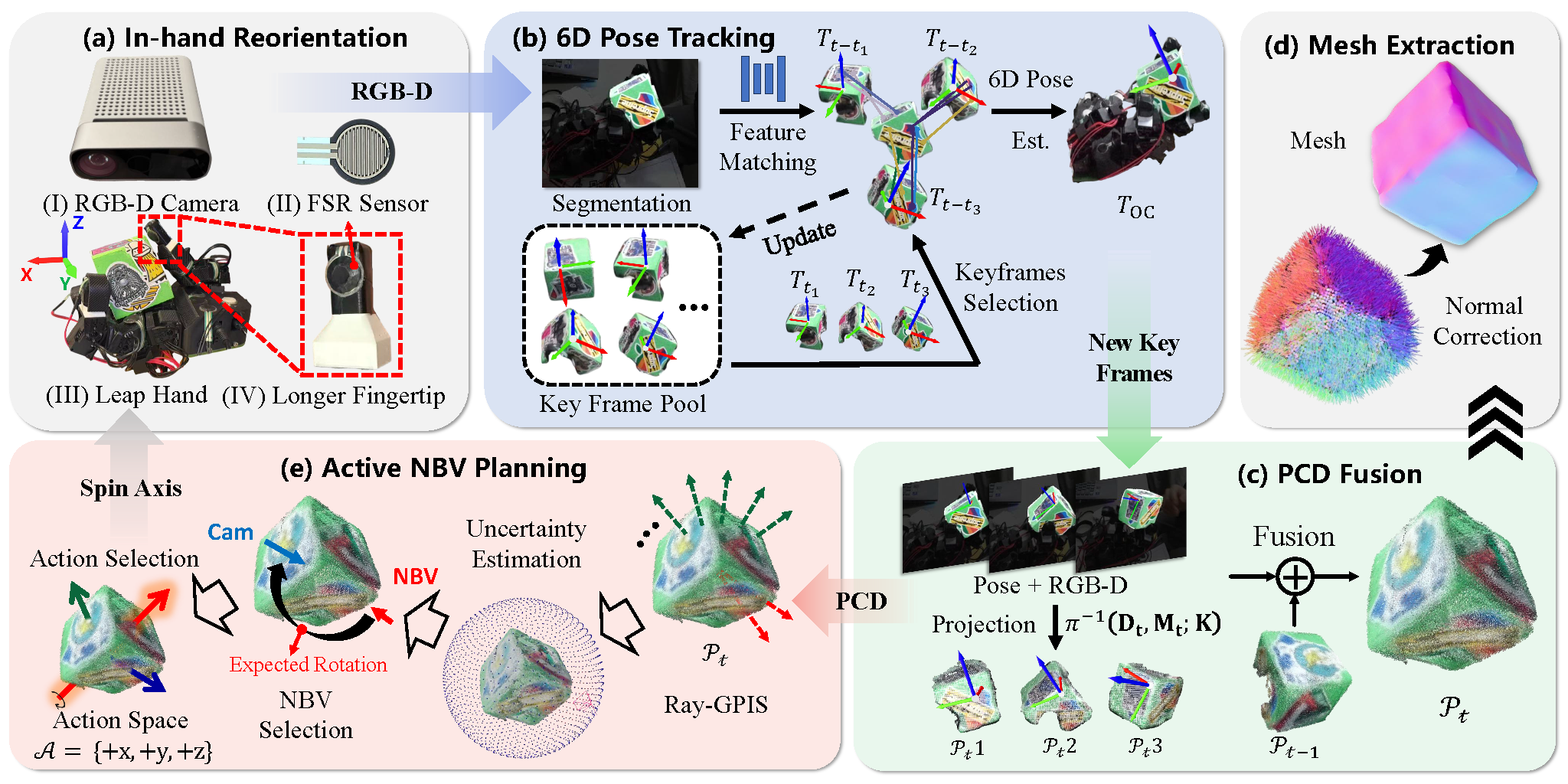
Pipeline
Overview of the proposed technical pipeline. The system integrates four modules: (a) in-hand object reorientation with the Leap Hand; (b) 6D pose tracking via BundleTrack; (c-d) reconstruction; (e) uncertainty-driven next-best-view planning.
Experiment I — Reconstruction Quality
We evaluate reconstruction performance on six graspable real-world objects under a fixed manipulation budget of 30 s. For each object, we show the qualitative results (RGB, online point cloud, offline refined mesh), followed by quantitative F-scores.
| Obj. | PCD–PCD (Online) | Mesh–Mesh (Offline) | ||||
|---|---|---|---|---|---|---|
| F@2 ↑ | F@5 ↑ | F@10 ↑ | F@2 ↑ | F@5 ↑ | F@10 ↑ | |
| Cube | 0.2895 | 0.9337 | 0.9977 | 0.6481 | 0.9557 | 0.9957 |
| Corner Block | 0.2353 | 0.7354 | 0.9303 | 0.5298 | 0.8559 | 0.9488 |
| L-shaped Block | 0.2306 | 0.8366 | 0.9886 | 0.4674 | 0.8367 | 0.9450 |
| Pepper | 0.1770 | 0.8321 | 0.9773 | 0.5480 | 0.8890 | 0.9913 |
| Cylinder | 0.4428 | 0.8400 | 0.9425 | 0.4035 | 0.8320 | 0.9372 |
| Cross Block | 0.1454 | 0.7718 | 0.9664 | 0.4601 | 0.8050 | 0.9850 |
| Mean | 0.2534 | 0.8249 | 0.9671 | 0.5095 | 0.8624 | 0.9672 |
| Std. | 0.1054 | 0.0679 | 0.0263 | 0.0855 | 0.0535 | 0.0262 |
Summary. Under a fixed 30 s manipulation budget, our framework delivers strong online reconstructions with an average F@10 = 0.9671 ± 0.0263 and F@5 = 0.8249 ± 0.0679. The offline refinement stage further improves geometric consistency and reduces residual artifacts, achieving F@10 = 0.9672 ± 0.0262 and F@5 = 0.8624 ± 0.0535. Remaining errors are primarily caused by sensing noise and small pose misalignments due to tracking inaccuracies.
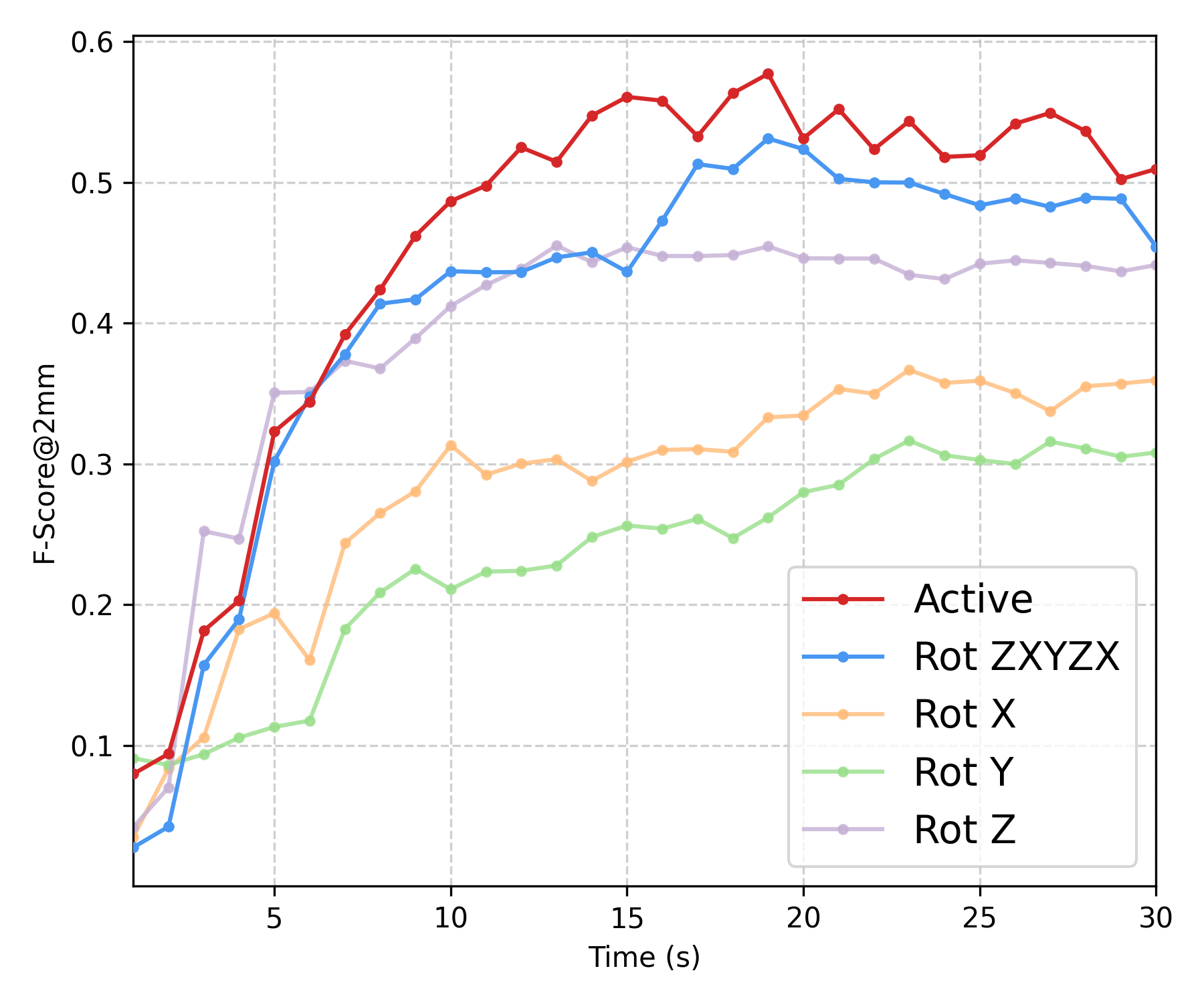
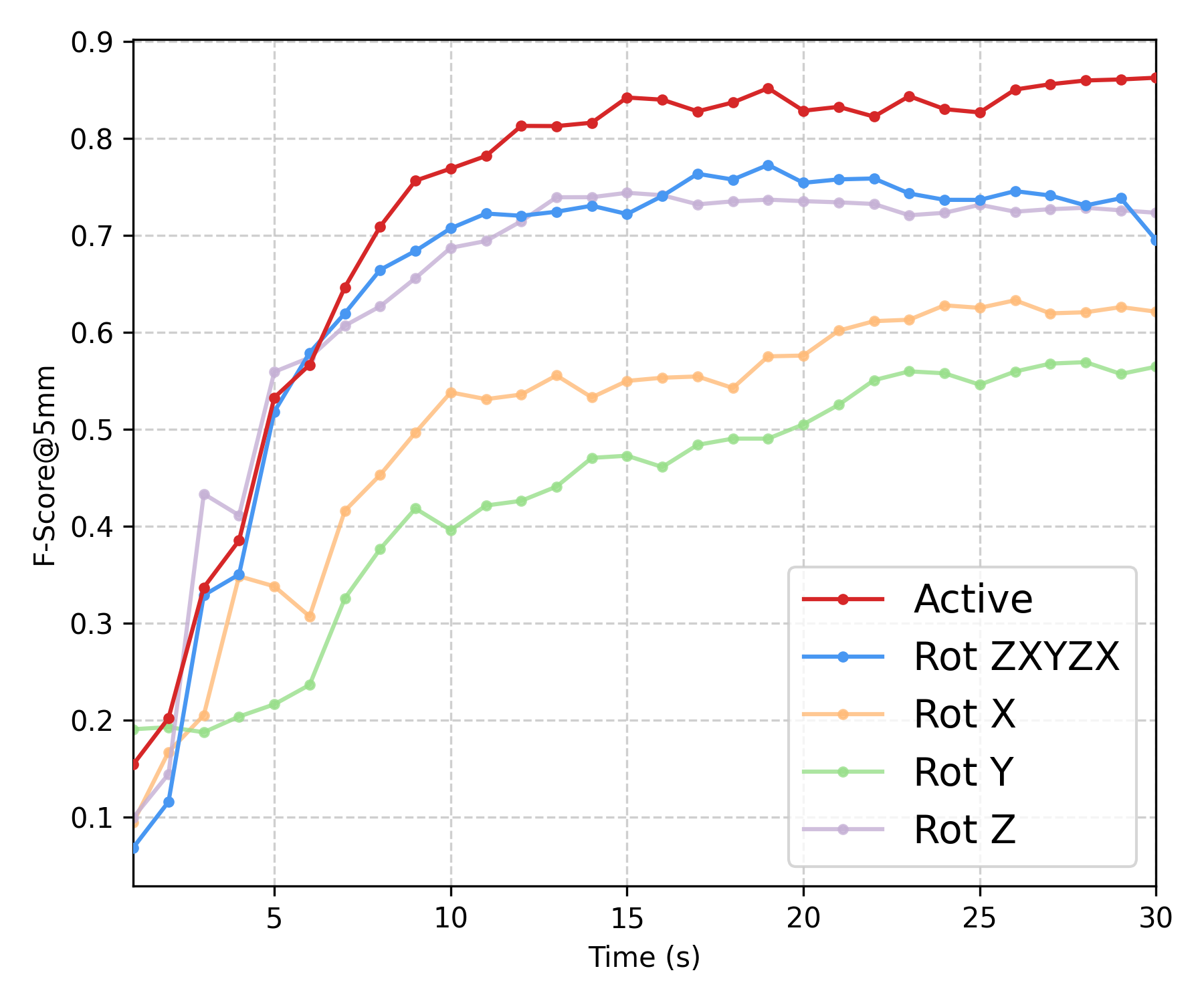
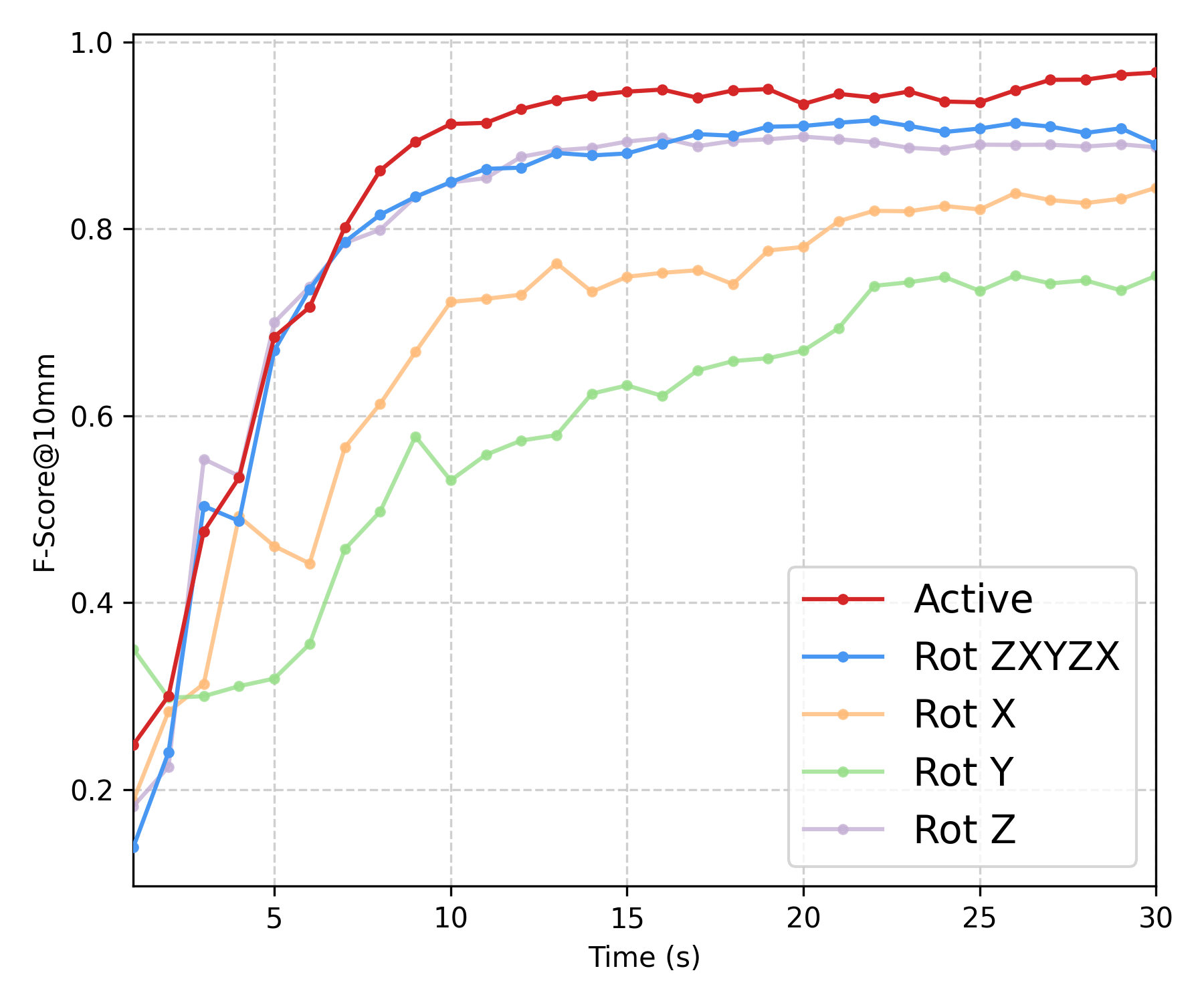
Experiment II — Efficiency vs Non-active Baselines
We compare five rotation strategies using the temporal evolution of the uncertainty tail \(q_{95}\) and Mesh--Mesh F-score at the 5mm threshold: ours, a fixed schedule \(z\!\rightarrow\!x\!\rightarrow\!y\!\rightarrow\!z\!\rightarrow\!x\), and single-axis baselines (\(x\)-only/\(y\)-only/\(z\)-only). Below, we show the offline refined meshes for all five strategies (normal colormap).
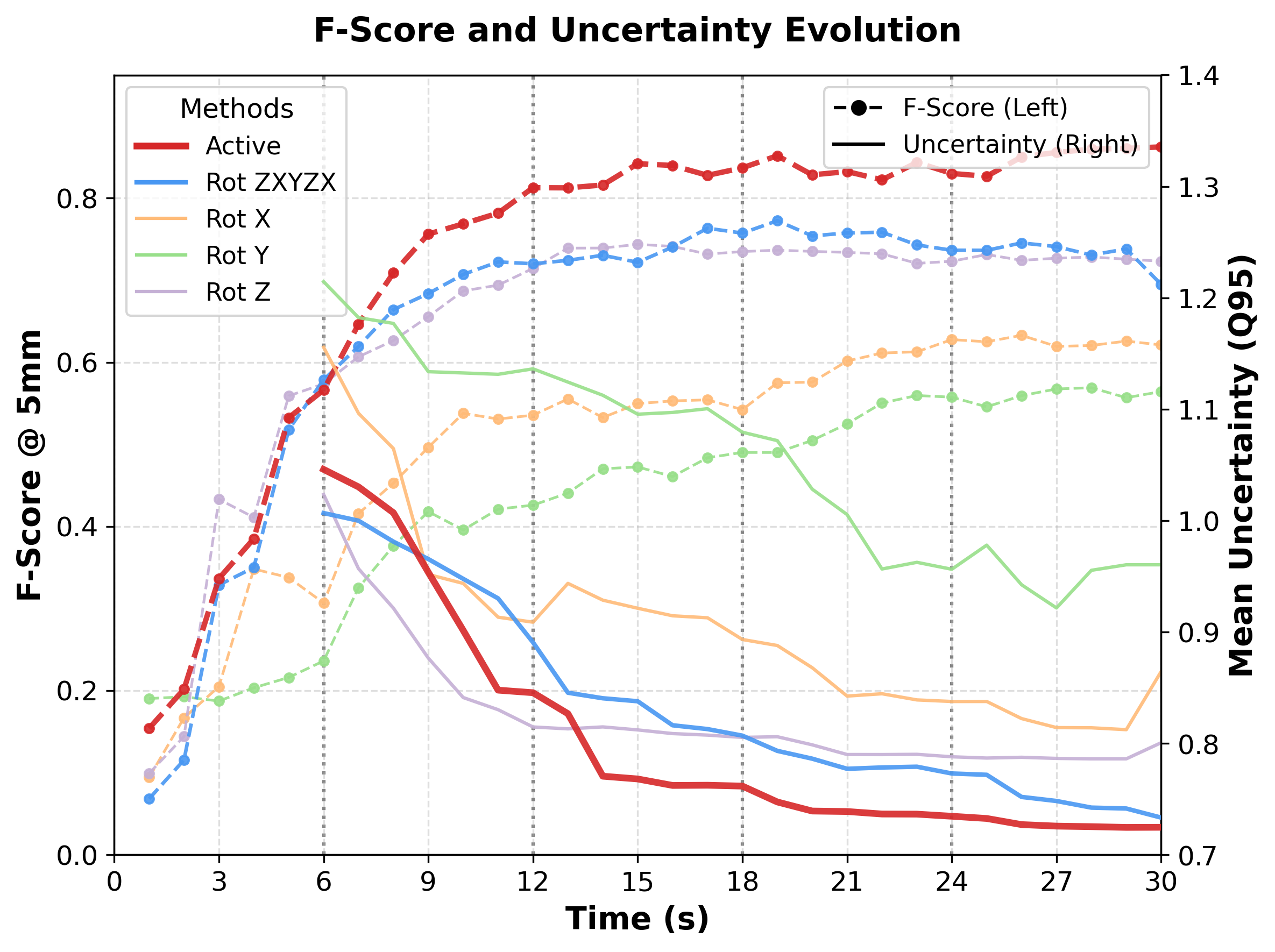
| Baseline | Mean PCD–PCD | Mean Mesh–Mesh | ||||
|---|---|---|---|---|---|---|
| \(F@2\ \uparrow\) | \(F@5\ \uparrow\) | \(F@10\ \uparrow\) | \(F@2\ \uparrow\) | \(F@5\ \uparrow\) | \(F@10\ \uparrow\) | |
| \(x\)-axis | 0.1735 | 0.6625 | 0.8655 | 0.3595 | 0.6211 | 0.8440 |
| \(y\)-axis | 0.1463 | 0.6074 | 0.7933 | 0.3082 | 0.5643 | 0.7498 |
| \(z\)-axis | 0.2079 | 0.7786 | 0.9228 | 0.4414 | 0.7231 | 0.8872 |
| Fixed schedule | 0.1550 | 0.7015 | 0.8995 | 0.4544 | 0.6948 | 0.8904 |
| Ours (Active) | 0.2534 | 0.8249 | 0.9671 | 0.5095 | 0.8624 | 0.9672 |

 (a)
(a)
 (b)
(b)
 (c)
(c)
Tip. Click the small Normals ▸ legend to expand/collapse the colorbar (so it never blocks the mesh).
Experiment III — Comparision with Single-View 3D Reconstruction Baselines
We further compare our method with recent single-view 3D reconstruction methods, TRELLIS.2 and SPAR3D, as reference baselines. For a well-defined comparison, we use the corresponding high-resolutionclean object image as input for each object. Because single-view methods do not preserve metric scale, we evaluate their meshes after post-hoc scale alignment to the ground truth; their scores therefore reflect scale-normalized shape similarity rather than directly usable metric reconstructions.
| Obj. | TRELLIS.2 | SPAR3D | Ours (AURORA) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| \(F@2\ \uparrow\) | \(F@5\ \uparrow\) | \(F@10\ \uparrow\) | \(F@2\ \uparrow\) | \(F@5\ \uparrow\) | \(F@10\ \uparrow\) | \(F@2\ \uparrow\) | \(F@5\ \uparrow\) | \(F@10\ \uparrow\) | |
| Cube | 0.8922 | 0.9324 | 0.9579 | 0.4510 | 0.5515 | 0.8968 | 0.6481 | 0.9557 | 0.9957 |
| Corner Block | 0.5140 | 0.6447 | 0.7833 | 0.4507 | 0.5331 | 0.8686 | 0.5298 | 0.8559 | 0.9488 |
| L-shaped Block | 0.8124 | 0.9251 | 0.9632 | 0.5209 | 0.7244 | 0.9987 | 0.4674 | 0.8367 | 0.9450 |
| Pepper | 0.6612 | 0.9504 | 0.9978 | 0.6998 | 0.9459 | 1.0000 | 0.5480 | 0.8890 | 0.9913 |
| Cylinder | 0.5884 | 0.8861 | 0.9423 | 0.9030 | 0.9963 | 1.0000 | 0.4035 | 0.8320 | 0.9372 |
| Cross Block | 0.4548 | 0.6509 | 0.7660 | 0.3176 | 0.6809 | 0.9260 | 0.4601 | 0.8050 | 0.9850 |
| Mean | 0.6538 | 0.8316 | 0.9018 | 0.5572 | 0.7387 | 0.9484 | 0.5095 | 0.8624 | 0.9672 |
Summary. Our method achieves higher mean Mesh--Mesh F-scores than TRELLIS.2 and SPAR3D at the \(5\,\mathrm{mm}\) and \(10\,\mathrm{mm}\) thresholds across all evaluated objects. This suggests that actively acquiring additional observations improves metric reconstruction over single-view priors, especially for objects with distinct geometric features. Nevertheless, single-view methods produce relatively clean meshes, highlighting a direction for us to make future improvements.
Discussion — Reference Comparison with Neural Feels
We compare AURORA with Neural Feels under a matched 30 s interaction budget on Pepper. In this setting, AURORA achieves higher F@5mm and reconstructs more complete geometry, benefiting from uncertainty-guided active replanning and multi-axis in-hand reorientation.
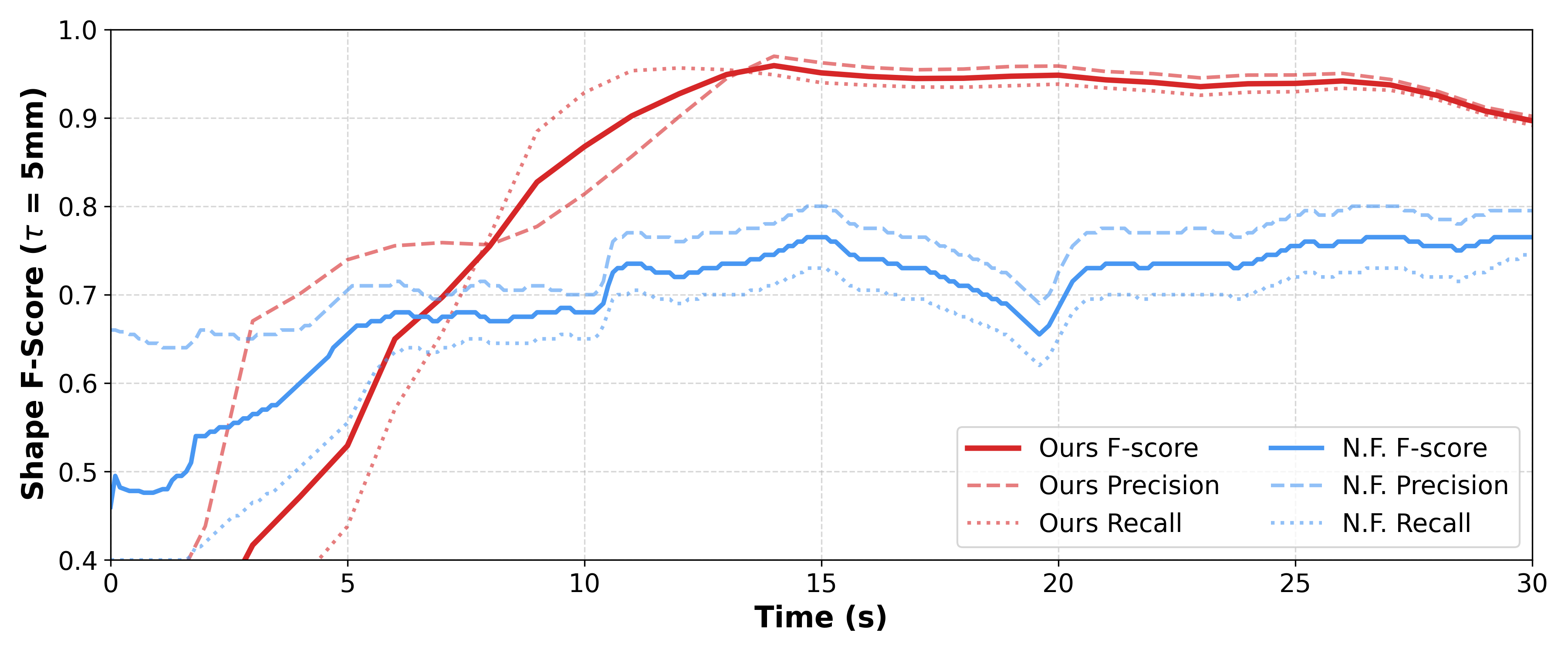
Efficiency. Neural Feels reports 417.13 s wall-clock reconstruction time from a 30 s observation window, while AURORA completes reconstruction in 71.82 s including mesh extraction, achieving about 5.8× lower latency. This efficiency mainly comes from our lightweight point-cloud fusion and planning pipeline, instead of optimizing a dense neural SDF.
Note. This is a reference comparison rather than a strictly controlled benchmark, since the two systems differ in hardware, tactile sensing, manipulation policy, task focus, and object instances. Therefore, the result should be interpreted as showing higher reconstruction efficiency in our current setting, rather than claiming that AURORA is universally superior to Neural Feels.